![]()
Work Queue User's Manual
Overview
Work Queue is a framework for building large scale manager-worker applications. Using the Work Queue library, you create a custom manager program that defines and submits a large number of small tasks. Each task is distributed to a remote worker process which executes it and returns the results. As results are created, the manager may generate more tasks to be executed. It is not unusual to write programs that distribute millions of tasks to thousands of remote workers.
Each worker process is a common executable that can be deployed within existing cluster and cloud systems, so it's easy to deploy a Work Queue application to run on machines that you already have access to. Whether you use a university batch system or a commercial cloud provider, your Work Queue application will be able to run there.
Work Queue is a production framework that has been used to create highly scalable scientific applications in high energy physics, bioinformatics, data mining, and other fields. It can also be used as an execution system for the Makeflow workflow engine. To see some of the Work Queue applications running right now, view the real time status page.
Quick Start in Python
There are a variety of ways to install Work Queue, depending on your local environment.
In most cases, installing via conda is the easiest method.
Please see our full installation instructions for other options.
First, Install Miniforge if you don't already have conda installed.
Then, open a terminal and install ndcctools like this:
conda install -c conda-forge ndcctoolsUsing a text editor, create a manager program called manager.py like this:
# Quick Start Example of Work Queue with Python Functions
# Import the Work Queue library.
import ndcctools.work_queue as wq
# Define a function to invoke remotely.
def my_sum(x, y):
import math
return x+y
# Create a new queue, listening on port 9123:
queue = wq.WorkQueue(9123)
print("listening on port {}".format(queue.port))
# Submit several tasks for execution:
print("submitting tasks...")
for value in range(1,100):
task = wq.PythonTask(my_sum, value, value)
task.specify_cores(1)
queue.submit(task)
# As they complete, display the results:
print("waiting for tasks to complete...")
while not queue.empty():
task = queue.wait(5)
if task:
print("task {} completed with result {}".format(task.id,task.output))
print("all done.")
Run the manager program at the command line like this:
python manager.pyIt should display output like this:
listening on port 9123
submitting tasks...
waiting for tasks to complete...The manager is now waiting for workers to connect and begin requesting work. (Without any workers, it will wait forever.) You can start one worker on the same machine by opening a new shell and running:
work_queue_worker localhost 9123The manager will send tasks to the worker for execution. As they complete, you will see output like this:
task 1 exited with output 10
task 2 exited with output 20
...
all done.(You can also declare and launch directly from python using the work queue factory.)
Congrats! You have now run a simple manager application that runs tasks on one local worker. Read on to learn how to build more complex applications and run large numbers of workers at scale.
Principle of Operation
A Work Queue application is a large parallel application consisting of a manager and multiple workers. The manager defines a large number of tasks, each of which is a discrete unit of work that can be executed in parallel. Each task is submitted to a queue, which makes it available for a worker to execute. Each worker connects to the manager, receives tasks to execute, and returns results back to the manager. The manager receives results in the order that they complete, and may submit further tasks as needed. Commonly used files are cached at each worker to speed up execution.
Tasks come in three types:
- A standard task is a single Unix command line to execute, along with its needed input files. Upon completion, it will produce one or more output files to be returned to the manager.
- A PythonTask is a single Python function to execute, along with its needed arguments. Each task is executed in its own python interpreter. Upon completion, it will produce a Python value (or an exception) as a result to return to the master.
- A RemoteTask is used to invoke serverless functions by name. The functions are executed by a specified long running coprocess at the workers (e.g. a python interpreter). Upon completion, it will produce a json response which will be returned to the manager.
All types of tasks share a common set of options. Each task can be labelled with the resources (CPU cores, GPU devices, memory, disk space) that it needs to execute. This allows each worker to pack the appropriate number of tasks. For example, a worker running on a 64-core machine could run 32 dual-core tasks, 16 four-core tasks, or any other combination that adds up to 64 cores. If you don't know the resources needed, you can enable a resource monitor to track and report what each task uses.
To run a large application at scale, you must start a number of Workers in parallel.
If you are using a university cluster or HPC system, then you will likely be submitting
the workers to a batch system such as HTCondor, SLURM, or UGE. If you are using a commercial
cloud, then you can run your workers inside of virtual machines. We provide a number of
scripts to facilitate starting workers this way, or you can arrange things yourself to
simply run the work_queue_worker executable.
Writing a Manager Program
A manager program can be written in Python, Perl, or C. In each language, the underlying principles are the same, but there are some syntactic differences shown below. The full API documentation for each language is here:
The basic outline of a Work Queue manager is:
- Create and configure the tasks' queue.
- Create tasks and add them to the queue.
- Wait for a task to complete.
- Process the result of one task.
- If more tasks are outstanding, return to step 3.
Creating a Queue
To begin, you must import the Work Queue library, and then create a WorkQueue object. You may specific a specific port number to listen on like this:
# Import the Work Queue library
import ndcctools.work_queue as wq
# Create a new queue listening on port 9123
q = wq.WorkQueue(9123)# Import the Work Queue library
use Work_Queue;
# Create a new queue listening on port 9123
my $q = Work_Queue->new(9123);/* Import the Work Queue library */
#include "work_queue.h"
/* Create a new queue listening on port 9123 */
struct work_queue *q = work_queue_create(9123);Of course, that specific port might already be in use, and so you may
specify zero to indicate any available port, and then use q.port to
discover which port was obtained:
# Create a new queue listening on any port
q = wq.WorkQueue(0)
print("listening on port {}".format(q.port))# Create a new queue listening on any port
my $q = Work_Queue->new(0);
printf("listening on port %d\n",q->port);/* Create a new queue listening on any port */
struct work_queue *q = work_queue_create(0);
printf("listening on port %d\n",work_queue_port(q));
Creating Standard Tasks
A standard task consists of a Unix command line to execute, along with a statement of what data is needed as input, and what data will be produced by the command. Input data can be provided in the form of a file or a local memory buffer. Output data can be provided in the form of a file or the standard output of the program.
Here is an example of a task that consists of the standard Unix gzip program,
which will read the file my-file and produce my-file.gz as an output:
t = wq.Task("./gzip < my-file > my-file.gz")my $t = Work_Queue::Task->new("./gzip < my-file > my-file.gz");struct work_queue_task *t = work_queue_task_create("./gzip < my-file > my-file.gz");It is not enough to simply state the command line. In addition, the input and output files associated with the task must be accurately stated. This is because the input files will be copied over to the worker, and the output files will be brough back to the manager.
In this example, the task will require my-file as an input file,
and produce my-file.gz as an output file. If the executable program
itself is not already installed at the worker, then it should also be
specified as an input file, so that it will be copied to the worker.
In addition, any input file that will remain unchanged through the course of the application should be marked as cacheable. This will allow the worker to keep a single copy of the file and share it between multiple tasks that need it.
Here is how to describe the files needed by this task:
# t.specify_input_file("name at manager", "name when copied at execution site", ...)
t.specify_input_file("/usr/bin/gzip", "gzip", cache = True)
t.specify_input_file("my-file", "my-file", cache = False)
t.specify_output_file("my-file.gz", "my-file.gz", cache = False)
# when the name at manager is the same as the exection site, we can write instead:
t.specify_input_file("my-file", cache = False)
t.specify_output_file("my-file.gz", cache = False)# $t->specify_input_file(local_name => "name at manager", remote_name => "name when copied at execution site", ...);
$t->specify_input_file(local_name => "/usr/bin/gzip", remote_name => "gzip", cache = True);
$t->specify_input_file(local_name => "my-file", remote_name => "my-file", cache = False);
$t->specify_output_file(local_name => "my-file.gz", remote_name => "my-file.gz", cache = False);
# when the name at manager is the same as the exection site, we can write instead:
$t->specify_input_file(local_name => "my-file", cache = False);
$t->specify_output_file(local_name => "my-file.gz", cache = False);# work_queue_task_specify_file(t, "name at manager", "name when copied at execution site", ...)
work_queue_task_specify_file(t, "/usr/bin/gzip", "gzip", WORK_QUEUE_INPUT, WORK_QUEUE_CACHE);
work_queue_task_specify_file(t, "my-file", "my-file", WORK_QUEUE_INPUT, WORK_QUEUE_NOCACHE);
work_queue_task_specify_file(t, "my-file.gz", "my-file.gz", WORK_QUEUE_OUTPUT, WORK_QUEUE_NOCACHE);When the task actually executes, the worker will create a sandbox directory,
which serves as the working directory for the task. Each of the input files
and directories will be copied into the sandbox directory.
The task outputs should be written into the current working directory.
The path of the sandbox directory is exported to
the execution environment of each worker through the WORK_QUEUE_SANDBOX shell
environment variable. This shell variable can be used in the execution
environment of the worker to describe and access the locations of files in the
sandbox directory.
Describing Tasks
In addition to describing the input and output files, you may optionally specify additional details about the task that will assist Work Queue in making good scheduling decisions.
If you are able, describe the resources needed by each task (cores, gpus, memory, disk) so that the worker can pack as many concurrent tasks. This is described in greater detail under Managing Resources.
You may also attach a tag to a task, which is just an user-defined string
that describes the purpose of the task. The tag is available as t.tag
when the task is complete.
t.specify_cores(2)
t.specify_memory(4096)
t.specify_tag("config-4.5.0")$t->specify_cores(2)
$t->specify_memory(4096)
$t->specify_tag("config-4.5.0")work_queue_task_specify_cores(t,2);
work_queue_task_specify_memory(t,4096);
work_queue_task_specify_tag(t,"config-4.5.0");Managing Tasks
Once a task has been fully specified, it can be submitted to the queue.
submit returns a unique taskid that can be helpful when later referring
to a task:
taskid = q.submit(t)my $taskid = $q->submit($t)int taskid = work_queue_submit(q,t);Once all tasks are submitted, use wait to wait until a task completes,
indicating how many seconds you are willing to pause. If a task completes
within that time limit, then wait will return that task object.
If no task completes within the timeout, it returns null.
while not q.empty():
t = q.wait(5)
if t:
print("Task {} has returned!".format(t.id))
if t.return_status == 0:
print("command exit code:\n{}".format(t.return_status))
print("stdout:\n{}".format(t.output))
else:
print("There was a problem executing the task.")while(not $q->empty()) {
my $t = $q->wait(5)
if($t) {
print("Task @{[$t->id]} has returned!\n");
if($t->{return_status} == 0) {
print("command exit code:\n@{[$t->{return_status}]}\n");
print("stdout:\n@{[$t->{output}]}\n");
} else {
print("There was a problem executing the task.\n");
}
}
}while(!work_queue_empty(q)) {
struct work_queue_task *t = work_queue_wait(q,5);
if(t) {
printf("Task %d has returned!\n", t->taskid);
if(t->return_status == 0) {
printf("command exit code: %d\n", t->return_status);
printf("stdout: %s\n", t->output);
} else {
printf("There was a problem executing the task.\n");
}
}
}A completed task will have its output files written to disk. You may examine
the standard output of the task in output and the exit code in
exit_status.
Note
The size of output is limited to 1 GB. Any output beyond 1 GB will be
truncated. So, please redirect the stdout ./my-command > my-stdout of the
task to a file and specify the file as an output file of the task as
described above.
When you are done with the task, delete it (only needed for C):
work_queue_task_delete(t);Continue submitting and waiting for tasks until all work is complete. You may
check to make sure that the queue is empty with work_queue_empty. When all
is done, delete the queue (only needed for C):
work_queue_delete(q);Full details of all of the Work Queue functions can be found in the Work Queue API.
Managing Python Tasks
A PythonTask is an extension of a standard task.
It is not defined with a command line to execute,
but with a Python function and its arguments, like this:
def my_sum(x, y):
return x+y
# task to execute x = my_sum(1, 2)
t = wq.PythonTask(my_sum, 1, 2)A PythonTask is handled in the same way as a standard task,
except that its output t.output is simply the Python return
value of the function. If the function should throw an exception,
then the output will be the exception object.
You can examine the result of a PythonTask like this:
while not q.empty():
t = q.wait(5)
if t:
x = t.output
if isinstance(x,Exception):
print("Exception: {}".format(x))
else:
print("Result: {}".format(x))A PythonTask is derived from Task and so all other methods for
controlling scheduling, managing resources, and setting performance options
all apply to PythonTask as well.
When running a Python function remotely, it is assumed that the Python interpreter and libraries available at the worker correspond to the appropiate python environment for the task. If this is not the case, an environment file can be provided with t.specify_environment:
t = wq.PythonTask(my_sum, 1, 2)
t.specify_environment("my-env.tar.gz")The file my-env.tar.gz is a
conda
environment created with conda-pack. A
minimal environment can be created a follows:
conda create -y -p my-env python=3.8 cloudpickle conda
conda install -y -p my-env -c conda-forge conda-pack
# conda install -y -p my-env pip and conda install other modules, etc.
conda run -p my-env conda-packSince every function needs to launch a fresh instance of the python intepreter,
overheads may dominate the execution for short running tasks (e.g. less than
30s). For such cases we recommend to use RemoteTask instead.
Running Managers and Workers
This section makes use of a simple but complete exmample of a Work Queue manager application to demonstrate various features.
Donload the example file for the language of your choice:
- Python: work_queue_example.py
- Perl: work_queue_example.pl
- C: work_queue_example.c
Language Specific Setup
Before running the application, you may need some additional setup, depending on the language in use:
Python Setup
If you installed via Conda, then no further setup is needed.
If you are running a Python application and did not install via Conda,
then you will need to set the PYTHONPATH to point to the cctools
installation, like this:
# Note: This is only needed if not using Conda:
$ PYVER=$(python -c 'import sys; print("%s.%s" % sys.version_info[:2])')
$ export PYTHONPATH=${HOME}/cctools/lib/python${PYVER}/site-packages:${PYTHONPATH}Perl Setup
If you are running a Perl application, you must set PERL5LIB to point to the Perl modules in cctools:
$ export PERL5LIB=${HOME}/cctools/lib/perl5/site_perl:${PERL5LIB}C Language Setup
If you are writing a Work Queue application in C, you should compile it into an executable with a command like this. Note that this example assumes that CCTools has
been installed using the conda method.
$ gcc work_queue_example.c -o work_queue_example -I${CONDA_PREFIX}/include/cctools -L${CONDA_PREFIX}/cctools/lib -lwork_queue -ldttools -lcrypto -lssl -lm -lzRunning a Manager Program
The example application simply compresses a bunch of files in parallel. The
files to be compressed must be listed on the command line. Each will be
transmitted to a remote worker, compressed, and then sent back to the Work
Queue manager. To compress files a, b, and c with this example
application, run it as:
# Python:
$ ./work_queue_example.py a b c
# Perl:
$ ./work_queue_example.pl a b c
# C
$ ./work_queue_example a b cYou will see this right away:
listening on port 9123...
submitted task: /usr/bin/gzip < a > a.gz
submitted task: /usr/bin/gzip < b > b.gz
submitted task: /usr/bin/gzip < c > c.gz
waiting for tasks to complete...The Work Queue manager is now waiting for workers to connect and begin requesting work. (Without any workers, it will wait forever.) You can start one worker on the same machine by opening a new shell and running:
# Substitute the IP or name of your machine for MACHINENAME.
$ work_queue_worker MACHINENAME 9123If you have access to other machines, you can simply ssh there and run workers as well. In general, the more you start, the faster the work gets done. If a
worker should fail, the work queue infrastructure will retry the work
elsewhere, so it is safe to submit many workers to an unreliable system.
Submitting Workers to a Batch System
If you have access to a HTCondor pool, you can use this shortcut to submit ten workers at once via HTCondor:
$ condor_submit_workers MACHINENAME 9123 10
Submitting job(s)..........
Logging submit event(s)..........
10 job(s) submitted to cluster 298.This will cause HTCondor to schedule worker jobs on remote machines. When they begin to run, they will call home to the indicated machine and port number, and begin to service the manager application.
Similar scripts are available for other common batch systems:
$ slurm_submit_workers MACHINENAME 9123 10
$ uge_submit_workers MACHINENAME 9123 10
$ pbs_submit_workers MACHINENAME 9123 10
$ torque_submit_workers MACHINENAME 9123 10When the manager completes, if the workers were not otherwise shut down,
they will still be available, so you can either run another manager
with the same workers, or you can remove the workers with kill, condor_rm,
or qdel as appropriate. If you forget to remove them, they will exit
automatically after fifteen minutes. (This can be adjusted with the -t
option to worker.)
Project Names and the Catalog Server
Keeping track of the manager's hostname and port can get cumbersome, especially if there are multiple managers. To help with this, a project name can be used to identify a Work Queue manager with a human-readable name. Work Queue workers can then be started for their managers by providing the project name instead of a host an port number.
The project name feature uses the Catalog Server to maintain and track the project names of managers and their respective locations. It works as follows: the manager advertises its project name along with its hostname and port to the catalog server. Work Queue workers that are provided with the manager's project name query the catalog server to find the hostname and port of the manager with the given project name.
For example, to have a Work Queue manager advertise its project name as
myproject, add the following code snippet after creating the queue:
q = wq.WorkQueue(name = "myproject")my $q = Work_Queue->new(name => "myproject");work_queue_specify_name(q, "myproject");To start a worker for this manager, specify the project name (myproject) to
connect in the -M option:
$ work_queue_worker -M myprojectYou can start ten workers for this manager on Condor using
condor_submit_workers by providing the same option arguments.:
$ condor_submit_workers -M myproject 10
Submitting job(s)..........
Logging submit event(s)..........
10 job(s) submitted to cluster 298.Or similarly on UGE using uge_submit_workers as:
$ uge_submit_workers -M myproject 10
Your job 153097 ("worker.sh") has been submitted
Your job 153098 ("worker.sh") has been submitted
Your job 153099 ("worker.sh") has been submitted
...Work Queue Status Display
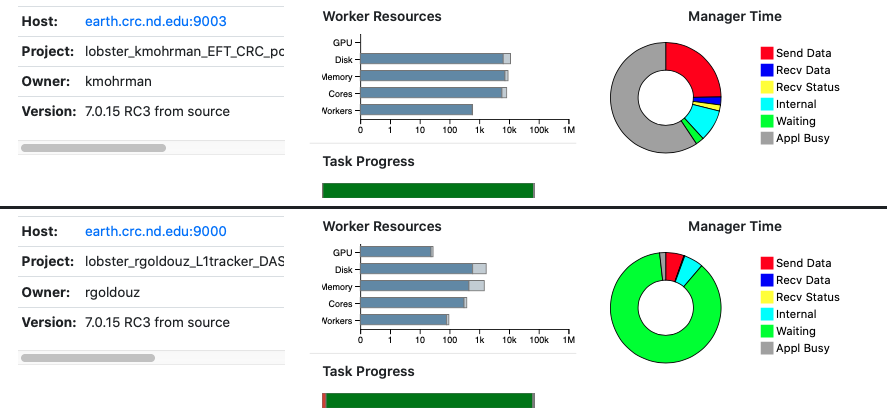
An additional benefit of using a project name is that you can now use the work_queue_status command to display the progress of your application. This shows the name, location, and statistics of each application that reports itself to the catalog server. (Note that this information is updated about once per minute.). For example:
% work_queue_status
PROJECT HOST PORT WAITING RUNNING COMPLETE WORKERS
molsim-c2h2 home.cse.nd.edu 8999 793 64 791 16
freds-model-search mars.indiana.edu 9123 100 700 1372 350
yang-analysis-355 login.crc.nd.edu 9100 8932 4873 10007 4873 The same information is available in a more graphical form online at the Work Queue Status Display, which looks like this:
Managing Workers with the Work Queue Factory
Instead of launching each worker manually from the command line, the utility
work_queue_factory may be used to launch workers are needed. The factory
will submit and maintain a number of workers according to the tasks available
in one or more managers.
For example, we can supply a minimum of 2 workers and a maximum of 10 to
a manager with the project name myproject via the condor batch system as follows:
work_queue_factory -Tcondor --min-workers=2 --max-workers=10 --manager-name myprojectThis arguments can be specified in a file. The factory will periodically re-read this file, which allows adjustments to the number of workers desired:
Configuarion file factory.json:
{
"manager-name": "myproject",
"max-workers": 10,
"min-workers": 2
}work_queue_factory -Tcondor -Cfactory.jsonFor further options, please refer to the work queue factory manual.
By default, the factory submits as many tasks that are waiting and running up to a specified maximum. To run more than one task in a worker, please refer to the following section on describing task resources and worker resources.
Using the factory with python
We can create a factory directly in python. Creating a factory object does not immediately launch it, so this is a good time to configure the resources, number of workers, etc. Factory objects function as Python context managers, so to indicate that a set of commands should be run with a factory running, wrap them in a with statement. The factory will be cleaned up automtically at the end of the block. As an example:
workers = work_queue.Factory("condor", "myproject")
workers.cores = 4
workers.memory = 4000
workers.disk = 5000
workers.max_workers = 20
with workers:
while not q.empty():
t = q.wait(5)
...Managing Resources
Unless otherwise specified, Work Queue assumes that a single task runs on a single worker at a time, and a single worker occupies an entire machine.
However, if the resources at a machine are larger than what you know a task requires, you most likely will want one worker to manage multiple tasks running on that machine. For example, if you have a 8-core machine, then you might want to run four 2-core tasks on a single worker at once, being careful not to exceed the available memory and disk.
Task Resources
To run several tasks in a worker, every task must have a description of the resources it uses, in terms of cores, memory, disk, and gpus. While time is not exactly a type of resource, specifying the running time of tasks can often be helpful to map tasks to workers. These resources can be specified as in the following example:
t.specify_cores(1) # task needs one core
t.specify_memory(1024) # task needs 1024 MB of memory
t.specify_disk(4096) # task needs 4096 MB of disk space
t.specify_gpus(0) # task does not need a gpu
t.specify_running_time_max(100) # task is allowed to run in 100 seconds
t.specify_running_time_min(10) # task needs at least 10 seconds to run (see work_queue_worker --wall-time option above)$t->specify_cores(1) # task needs one core
$t->specify_memory(1024) # task needs 1024 MB of memory
$t->specify_disk(4096) # task needs 4096 MB of disk space
$t->specify_gpus(0) # task does not need a gpu
$t->specify_running_time_max(100) # task is allowed to run in 100 seconds
$t->specify_running_time_min(10) # task needs at least 10 seconds to run (see work_queue_worker --wall-time option above)work_queue_task_specify_cores(t,1) # task needs one core
work_queue_task_specify_memory(t,1024) # task needs 1024 MB of memory
work_queue_task_specify_disk(t,4096) # task needs 4096 MB of disk space
work_queue_task_specify_gpus(t,0) # task does not need a gpu
work_queue_task_specify_running_time_max(t,100) # task is allowed to run in 100 seconds
work_queue_task_specify_running_time_min(t,10) # task needs at least 10 seconds to run (see work_queue_worker --wall-time option above)When the maximum running time is specified, taskvine will kill any task that exceeds its maximum running time. The minimum running time, if specified, helps Work Queue decide which worker best fits which task. Specifying tasks' running time is especially helpful in clusters where workers may have a hard threshold of their running time.
Resources are allocated according to the following rules:
- If the task does not specify any resources, then it is allocated a whole worker.
- The task will be allocated as least as much of the value of the resources specified. E.g., a task that specifies two cores will be allocated at least two cores.
- If gpus remain unspecified, then the task is allocated zero gpus.
- If a task specifies gpus, but does not specify cores, then the task is allocated zero cores.
- In all other cases, cores, memory, and disk of the worker are divided evenly according to the maximum proportion of specified task requirements over worker resources. The proportions are rounded up so that only whole number of tasks could fit in the worker.
As an example, consider a task that only specifies 1 core, and does not specify any other resource, and a worker with 4 cores, 12 GB of memory, and 36 GB of disk. According to the rules above:
- Rule 1 does not apply, as at least one resource (cores) was specified.
- According to rule 2, the task will get at least one core.
- According to rule 3, the task will not be allocated any gpus.
- Rule 4 does not apply, as no gpus were specified, and cores were specified.
- For rule 5, the task requires 1 core, and the worker has 4 cores. This gives a proportion of 1/4=0.25. Thus, the task is assigned 25% of the memory and disk (3 GB and 9 GB respectively).
As another example, now assume that the task specifies 1 cores and 6 GB of memory:
- Rules 1 to 4 are as the last example, only that now the task will get at least 6 GB of memory.
- From cores we get a proportion of 1/4=0.25, and from memory 6GB/12GB=0.5. The memory proportion dictates the allocation as it is the largest. This means that the task will get assigned 50% of the cores (2), memory (6 GB), and disk (18 GB).
Note that proportions are 'rounded up', as the following example shows. Consider now that the task requires 1 cores, 6GB of memory, and 27 GB of disk:
- Rules 1 to 4 are as before, only that now the worker will get at least 30 GB of disk.
- The proportions are 1/4=0.25 for cores, 6GB/12GB=0.5 for memory, and 27GB/36GB=0.75 for disk. This means we would assign 3 cores, 9 memory, and 27 to the task. However, this would mean that no other task of this size would be able to run in the worker. Rather than assign 75% of the resources, and risk an preventable failure because of resource exhaustion, the task is assigned 100% of the resources from the worker. More generally, allocations are rounded up so that only a whole number of tasks can be fit in the worker.
Note
If you want Work Queue to exactly allocate the resources you have
specified, use the proportional-resources and proportional-whole-tasks
parameters as shown here. In
general, however, we have found that using proportions nicely adapts to the
underlying available resources, and leads to very few resource exhaustion
failures while still using worker resources efficiently.
The current Work Queue implementation only accepts whole integers for its resources, which means that no worker can concurrently execute more tasks than its number of cores. (This will likely change in the future.)
When you would like to run several tasks in a worker, but you are not sure about the resources each task needs, Work Queue can automatically find values of resources that maximize throughput, or minimize waste. This is discussed in the section below.
Worker Resources
By default, a worker tries to use all the resources of the machine it is running. The resources detected are displayed when the worker starts up, for example:
work_queue_worker: creating workspace /tmp/worker-102744-8066
work_queue_worker: using 16 cores, 15843 MB memory, 61291 MB disk, 0 gpusYou can manually adjust the resources managed by a worker like this:
$ work_queue_worker --cores 8 --memory 1000 --disk 8000 --gpus 1 ...other options...Unlike other resources, the default value for gpus is 0. You can use the
command line option --gpus to declare how many gpus are available at a
worker.
When the lifetime of the worker is known, for example, the end of life of a lease, this information can be communicated to the worker as follows. For example, if the worker will be terminated in one hour:
$ work_queue_worker --wall-time 3600 ...other options...In combination with the worker option --wall-time, tasks can request a
minimum time to execute with specify_running_time_min, as explained (below)[#specifying-task-resources].
You may also use the same --cores, --memory, --disk, and --gpus options when using
batch submission scripts such as condor_submit_workers or
slurm_submit_workers, and the script will correctly ask the batch system for
a node of the desired size.
The only caveat is when using uge_submit_workers, as there are many
differences across systems that the script cannot manage. For uge_submit_workers you have to specify both the resources used by the
worker (i.e., with --cores, etc.) and the appropiate computing node with the -p option.
For example, say that your local UGE installation requires you to specify the
number of cores with the switch -pe smp , and you want workers with 4
cores:
$ uge_submit_workers --cores 4 -p "-pe smp 4" MACHINENAME 9123If you find that there are options that are needed everytime, you can compile
CCTools using the --uge-parameter. For example, at Notre Dame we
automatically set the number of cores as follows:
$ ./configure --uge-parameter '-pe smp $cores'So that we can simply call:
$ uge_submit_workers --cores 4 MACHINENAME 9123The variables $cores, $memory, and $disk, have the values of the
options passed to --cores, --memory, --disk.
Factory Resources
The work_queue_factory accepts the arguments --cores, --memory,
--disk, and --gpus to specify the size of the desired workers. Resources may also be
specified in the configuration file as follows:
{
"manager-name": "myproject",
"max-workers": 4,
"min-workers": 1,
"cores": 4,
"memory": 4096,
"disk": 4096,
"gpus": 1
}Both memory and disk are specified in MB.
Monitoring and Enforcement
So far we have used resources values simply as hints to Work Queue to schedule concurrent tasks at workers. By default, Work Queue does not monitor or enforce these limits. You can enable monitoring and enforcement as follows:
# Measure the resources used by tasks, and terminate tasks that go above their
# resources:
q.enable_monitoring()
# Measure the resources used by tasks, but do not terminate tasks that go above
# declared resources:
q.enable_monitoring(watchdog=False)# Measure the resources used by tasks, and terminate tasks that go above their
# resources:
$q->enable_monitoring()
# Measure the resources used by tasks, but do not terminate tasks that go above
# declared resources:
$q->enable_monitoring(watchdog => 0)# Measure the resources used by tasks, and terminate tasks that go above their
# resources:
work_queue_enable_monitoring(q,0,0)
# Measure the resources used by tasks, but do not terminate tasks that go above
# declared resources:
work_queue_enable_monitoring(q,0,1)When monitoring is enabled, you can explore the resources measured when a task returns:
t = q.wait(5)
if t:
print("Task used {} cores, {} MB memory, {} MB disk",
t.resources_measured.cores,
t.resources_measured.memory,
t.resources_measured.disk)
print("Task was allocated {} cores, {} MB memory, {} MB disk",
t.resources_requested.cores,
t.resources_requested.memory,
t.resources_requested.disk)
if t.limits_exceeded and t.limits_exceeded.cores > -1:
print("Task exceeded its cores allocation.")my $t = $q=>wait(5)
if($t) {
say("Task used %f cores, %f MB memory, %f MB disk",
$t->resources_measured->{cores},
$t->resources_measured->{memory},
$t->resources_measured->{disk})
say("Task was allocated %f cores, %f MB memory, %f MB disk",
$t.resources_requested->{cores},
$t.resources_requested->{memory},
$t.resources_requested->{disk})
if($t->limits_exceeded and $t->limits_exceeded->{cores} > -1) {
say("Task exceeded its cores allocation.")
}
}work_queue_task *t = work_queue_wait(q,5);
if(t) {
printf("Task used %f cores, %f MB memory, %f MB disk",
t->resources_measured->cores,
t->resources_measured->memory,
t->resources_measured->disk);
printf("Task was allocated %f cores, %f MB memory, %f MB disk",
t->resources_requested->cores,
t->resources_requested->memory,
t->resources_requested->disk});
if(t->limits_exceeded && t->limits_exceeded->cores > -1) {
printf("Task exceeded its cores allocation.")
}
}Alternatively, when you declare a task (i.e., before submitting it), you can
declare a directory to which a report of the resources will be written. The
report format is JSON, as its filename has the form
wq-PID_OF_MANAGER-task-TASK_ID.summary.
t = wq.Task(...)
t.specify_monitor_output("my-resources-output")
...
taskid = q.submit(t)$t = WorkQueue::Task->new(...)
$t->specify_monitor_output("my-resources-output")
...
taskid = $q->submit($t)struct work_queue_task *t = work_queue_task_create(...);
work_queue_specify_monitor_output("my-resources-output");
...
int taskid = work_queue_submti(q, t);Work Queue also measures other resources, such as peak bandwidth,
bytes_read, bytes_written, bytes_sent, bytes_received,
total_files, cpu_time, and wall_time.
Grouping Tasks with Similar Resource Needs
Several tasks usually share the same resource description, and to this end, Work Queue allows you to tasks into groups called categories. You can attach resource descriptions to each category, and then label a task to set it as part of a category.
We can create some categories with their resource description as follows:
# memory and disk values in MB.
q.specify_category_max_resources('my-category-a', {'cores': 2, 'memory': 1024, 'disk': 2048, 'gpus': 0})
q.specify_category_max_resources('my-category-b', {'cores': 1})
q.specify_category_max_resources('my-category-c', {})# memory and disk values in MB.
$q->specify_category_max_resources('my-category-a', {'cores' => 2, 'memory' => 1024, 'disk' => 2048, 'gpus' => 0})
$q->specify_category_max_resources('my-category-b', {'cores' => 1})
$q->specify_category_max_resources('my-category-c', {})# memory and disk values in MB.
struct rmsummary *ra = rmsummary_create(-1);
ra->cores = 2;
ra->memory = 1024;
ra->disk = 2048;
work_queue_specify_max_resources("my-category-a", ra);
rmsummary_delete(ra);
struct rmsummary *rb = rmsummary_create(-1);
rb->cores = 1;
work_queue_specify_max_resources("my-category-b", rb);
rmsummary_delete(rb);
work_queue_specify_max_resources("my-category-c", NULL);In the previous examples, we created three categories. Note that it is not necessary to specify all the resources, as Work Queue can be directed to compute some efficient defaults. To assign a task to a category:
t.specify_category('my-category-a')$t->specify_category('my-category-a')work_queue_task_specify_category(t,"my-category-a")When a category leaves some resource unspecified, then Work Queue tries to find some reasonable defaults in the same way described before in the section (Specifying Task Resources)[#specifying-task-resources].
Warning
When a task is declared as part of a category, and also has resources
specified directly with calls such as t.specify_cores, the resources
directly specified take precedence over the category declaration for that
task
When the resources used by a task are unknown, Work Queue can measure and compute efficient resource values to maximize throughput or minimize waste, as we explain in the following sections.
Automatic Resource Management
If the resources a category uses are unknown, then Work Queue can be directed
to find efficient resource values to maximize throughput or minimize resources
wasted. In these modes, if a value for a resource is specified with
specify_max_resources, then it is used as a theoretical maximum.
When automatically computing resources, if any of cores, memory or disk are
left unspecified in specify_max_resources, then Work Queue will run some
tasks using whole workers to collect some resource usage statistics. If all
cores, memory, and disk are specified, then Work Queue uses these maximum
values instead of using whole workers. As before, unspecified gpus default to 0.
Once some statistics are available, further tasks may run with smaller
allocations if such a change would increase throughput. Should a task exhaust
its resources, it will be retried using the values of specify_max_resources,
or a whole worker, as explained before.
Automatic resource management is enabled per category as follows:
q.enable_monitoring()
q.specify_category_max_resources('my-category-a', {})
q.specify_category_mode('my-category-a', q.WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT)
q.specify_category_max_resources('my-category-b', {'cores': 2})
q.specify_category_mode('my-category-b', q.WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT)$q->enable_monitoring()
$q->specify_category_max_resources('my-category-a', {})
$q->specify_category_mode('my-category', q.WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT)
$q->specify_category_max_resources('my-category-b', {'cores' => 2})
$q->specify_category_mode('my-category', q.WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT)work_queue_enable_monitoring(q,0,0);
work_queue_specify_category_max_resources(q, "my-category-a", NULL);
work_queue_specify_category_mode(q, "my-category-a", WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT);
struct rmsummary *r = rmsummary_create(-1);
r->cores = 2;
work_queue_specify_category_max_resources(q, "my-category-b", r);
work_queue_specify_category_mode(q, "my-category-b", WORK_QUEUE_ALLOCATION_MODE_MAX_THROUGHPUT);
rmsummary_delete(r);In the previous examples, tasks in 'my-category-b' will never use more than two cores, while tasks in 'my-category-a' are free to use as many cores as the largest worker available if needed.
You can set a limit on the minimum resource value a category can use. The automatic resource computation will never go below the values specified:
q.specify_category_min_resources('my-category-a', {'memory': 512})$q->specify_category_min_resources('my-category-a', {'memory' => 512})struct rmsummary *r = rmsummary_create(-1);
r->memory = 512;
$q->specify_category_min_resources("my-category-a", r);
rmsummary_delete(r);You can enquire about the resources computed per category with
work_queue_status:
$ work_queue_status -A IP-OF-MACHINE-HOSTING-WQ PORT-OF-WQ
CATEGORY RUNNING WAITING FIT-WORKERS MAX-CORES MAX-MEMORY MAX-DISK
analysis 216 784 54 4 ~1011 ~3502
merge 20 92 30 ~1 ~4021 21318
default 1 25 54 >1 ~503 >243In the above, we have three categories, with RUNNING and WAITING tasks. The
column FIT-WORKERS shows the count of workers that can fit at least one task in
that category using the maximum resources either set or found. Values for max
cores, memory and disk have modifiers ~ and > as follows:
- No modifier: The maximum resource usage set with
specify_category_max_resources, or set for any task in the category via calls such asspecify_cores. - ~: The maximum resource usage so far seen when resource is left unspecified in
specify_category_max_resources. All tasks so far have run with no more than this resource value allocated. -
: The maximum resource usage that has caused a resource exhaustion. If this value is larger than then one specified with
specify_category_max_resources, then tasks that exhaust resources are not retried. Otherwise, if a maximum was not set, the tasks will be retried in larger workers as workers become available.
Warning
When resources are specified directly to the task with calls such as
t.specify_cores, such resources are fixed for the task and are not
modified when more efficient values are found.
Advanced Techniques
A variety of advanced features are available for programs with unusual needs or very large scales. Each feature is described briefly here, and more details may be found in the Work Queue API.
Security
By default, Work Queue does not perform any encryption or authentication, so any workers will be able to connect to your manager, and vice versa. This may be fine for a short running anonymous application, but is not safe for a long running application with a public name.
Currently, Work Queue uses SSL to provide communication encryption, and a password file to provide worker-manager authentication. These features can be enabled independet of each other.
SSL support
Work Queue can encrypt the communication between manager and workers using SSL. For this, you need to specify the key and certificate (in PEM format) of your server when creating the queue.
If you do not have a key and certificate at hand, but you want the communications to be encrypted, you can create your own key and certificate:
# Be aware that since this certificate would not be signed by any authority, it
# cannot be used to prove the identity of the server running the manager.
openssl req -x509 -newkey rsa:4096 -keyout MY_KEY.pem -out MY_CERT.pem -sha256 -days 365 -nodesTo activate SSL encryption, indicate the paths to the key and certificate when creating the queue:
# Import the Work Queue library
import ndcctools.work_queue as wq
q = wq.WorkQueue(port=9123, ssl=('MY_KEY.pem', 'MY_CERT.pem'))
# Alternatively, you can set ssl=True and let the python API generate
# temporary ssl credentials for the queue:
q = wq.WorkQueue(port=9123, ssl=True)/* Import the Work Queue library */
#include "work_queue.h"
/* Create a new queue listening on port 9123 */
struct work_queue *q = work_queue_ssl_create(9123, 'MY_KEY.pem', 'MY_CERT.pem');If you are using a (project name)[#project-names-and-the-catalog-server] for
your queue, then the workers will be aware that the manager is using SSL and
communicate accordingly automatically. However, you are directly specifying the
address of the manager when launching the workers, then you need to add the
--ssl flag to the command line, as:
work_queue_worker (... other args ...) --ssl HOST PORT
work_queue_factory (... other args ...) --ssl HOST PORT
work_queue_status --ssl HOST PORT
condor_submit_workers -E'--ssl' HOST PORTPassword Files
We recommend that you enable a password for your applications. Create a file
(e.g. mypwfile) that contains any password (or other long phrase) that you
like (e.g. This is my password). The password will be particular to your
application and should not match any other passwords that you own. Note that
the contents of the file are taken verbatim as the password; this means that
any new line character at the end of the phrase will be considered as part of
the password.
Then, modify your manager program to use the password:
q.specify_password_file("mypwfile")$q->specify_password_file("mypwfile");work_queue_specify_password_file(q,"mypwfile");And give the --password option to give the same password file to your
workers:
$ work_queue_worker --password mypwfile -M myprojectWith this option enabled, both the manager and the workers will verify that the other has the matching password before proceeding. The password is not sent in the clear, but is securely verified through a SHA1-based challenge-response protocol.
Maximum Retries
When a task cannot be completed because a worker disconnection or because it exhausted some intermediate resource allocation, it is automatically retried. By default, there is no limit on the number of retries. However, you can set a limit on the number of retries:
t.specify_max_retries(5) # Task will be try at most 6 times (5 retries).$t->specify_max_retries(5) # Task will be try at most 6 times (5 retries).work_queue_specify_max_retries(t, 5)When a task cannot be completed in the specified number of tries,
then the task result is set to WORK_QUEUE_RESULT_MAX_RETRIES.
Pipelined Submission
If you have a very large number of tasks to run, it may not be possible to
submit all of the tasks, and then wait for all of them. Instead, submit a
small number of tasks, then alternate waiting and submitting to keep a constant
number in the queue. The hungry will tell you if more submission are
warranted:
if q.hungry():
# submit more tasks...if($q->hungry()) {
# submit more tasks...
}if(work_queue_hungry(q)) {
// submit more tasks...
}Fetching Input Data via URL
Tasks can fetch remote data named by a URL into the worker's cache.
For example, if you have a large dataset provided by a web server,
use specify_url to attach the URL to a local file. The data
will be downloaded once per worker and then shared among all
tasks that require it:
t.specify_url("http://somewhere.com/data.tar.gz", "data.tar.gz", type=WORK_QUEUE_INPUT, cache=True)$t->specify_url("http://somewhere.com/data.tar.gz", "data.tar.gz", type=WORK_QUEUE_INPUT, flags=wq.WORK_QUEUE_CACHE)work_queue_task_specify_url(t,"http://somewhere.com/data.tar.gz", "data.tar.gz", WORK_QUEUE_INPUT, WORK_QUEUE_CACHE)(Note that specify_url does not currently support output data.)
Fetching Input Data via Command
Input data for tasks can also be produced at the worker by arbitrary
shell commands. The output of these commands can be cached and shared
among multiple tasks. This is particularly useful for unpacking or
post-processing downloaded data. For example, to download data.tar.gz from
a URL and then unpack into the directory data:
t.specify_file_command("curl http://somewhere.com/data.tar.gz | tar cvzf -", "data" , type=WORK_QUEUE_INPUT, cache=True)$t->specify_file_command("curl http://somewhere.com/data.txt | tar cvzf -", "data", type=wq.WORK_QUEUE_INPUT, flags=wq.WORK_QUEUE_CACHE)work_queue_task_specify_file_command(t,"curl http://somewhere.com/data.txt | tar cvzf -", "data", WORK_QUEUE_INPUT, WORK_QUEUE_CACHE)(Note that specify_file_command does not currently support output data.)
Watching Output Files
If you would like to see the output of a task as it is produced, add
WORK_QUEUE_WATCH to the flags argument of specify_file. This will
cause the worker to periodically send output appended to that file back to the
manager. This is useful for a program that produces a log or progress bar as
part of its output.
t.specify_output_file("my-file", flags = wq.WORK_QUEUE_WATCH)$t->specify_output_file(local_name => "my-file", flags = wq.WORK_QUEUE_WATCH)work_queue_task_specify_file(t, "my-file", "my-file", WORK_QUEUE_OUTPUT, WORK_QUEUE_WATCH);Optional Output Files
It is sometimes useful to return an output file only in the case of a failed task.
For example, if your task generates a very large debugging output file debug.out,
then you might not want to keep the file if the task succeeded. In this case,
you can add the WORK_QUEUE_FAILURE_ONLY flag to indicate that a file should
only be returned in the event of failure:
t.specify_output_file("debug.out", flags = wq.WORK_QUEUE_FAILURE_ONLY)$t->specify_output_file(local_name => "debug.out", flags = wq.WORK_QUEUE_FAILURE_ONLY)work_queue_task_specify_file(t, "debug.out", "debug.out", WORK_QUEUE_OUTPUT, WORK_QUEUE_FAILURE_ONLY);In a similar way, the WORK_QUEUE_SUCCESS_ONLY flag indicates that an output file
should only be returned if the task actually succeeded.
Fast Abort
A large computation can often be slowed down by stragglers. If you have a large number of small tasks that take a short amount of time, then Fast Abort can help. The Fast Abort feature keeps statistics on tasks execution times and proactively aborts tasks that are statistical outliers:
# Disconnect workers that are executing tasks twice as slow as compared to the average.
q.activate_fast_abort(2)# Disconnect workers that are executing tasks twice as slow as compared to the average.
$q->activate_fast_abort(2);// Disconnect workers that are executing tasks twice as slow as compared to the average.
work_queue_activate_fast_abort(q, 2);Tasks that trigger fast abort are automatically retried in some other worker. Each retry allows the task to run for longer and longer times until a completion is reached. You can set an upper bound in the number of retries with Maximum Retries.
String Interpolation
If you have workers distributed across multiple operating systems (such as Linux, Cygwin, Solaris) and/or architectures (such as i686, x86_64) and have files specific to each of these systems, this feature will help. The strings $OS and $ARCH are available for use in the specification of input file names. Work Queue will automatically resolve these strings to the operating system and architecture of each connected worker and transfer the input file corresponding to the resolved file name. For example:
t.specify_input_file("my-executable.$OS.$ARCH", "my-exe")$t->specify_output_file(local_name => "my-executable.$OS.$ARCH", remote_name => "my-exe");work_queue_task_specify_file(t,"my-executable.$OS.$ARCH","./my-exe",WORK_QUEUE_INPUT,WORK_QUEUE_CACHE);This will transfer my-executable.Linux.x86_64 to workers running on a Linux
system with an x86_64 architecture and a.Cygwin.i686 to workers on Cygwin
with an i686 architecture.
Note this feature is specifically designed for specifying and distingushing input file names for different platforms and architectures. Also, this is different from the $WORK_QUEUE_SANDBOX shell environment variable that exports the location of the working directory of the worker to its execution environment.
Task Cancellations
This feature is useful in workflows where there are redundant tasks or tasks
that become obsolete as other tasks finish. Tasks that have been submitted can
be cancelled and immediately retrieved without waiting for Work Queue to
return them in work_queue_wait. The tasks to cancel can be identified by
either their taskid or tag. For example:
# create task as usual and tag it with an arbitrary string.
t = wq.Task(...)
t.specify_tag("my-tag")
taskid = q.submit(t)
# cancel task by id. Return the canceled task.
t = q.cancel_by_taskid(taskid)
# or cancel task by tag. Return the canceled task.
t = q.cancel_by_tasktag("my-tag")# create task as usual and tag it with an arbitrary string.
my $t = Work_Queue::Task->new(...)
my $t->specify_tag("my-tag")
my taskid = $q->submit($t);
# cancel task by id. Return the canceled task.
$t = $q->cancel_by_taskid(taskid);
# or cancel task by tag. Return the canceled task.
$t = $q->cancel_by_tasktag("my-tag");// create task as usual and tag it with an arbitrary string.
struct work_queue_task *t = work_queue_task_create("...");
work_queue_specify_task(t, "my-tag");
int taskid = work_queue_submit(q, t);
// cancel task by id. Return the canceled task.
t = work_queue_cancel_by_taskid(q, taskid);
# or cancel task by tag. Return the canceled task.
t = work_queue_cancel_by_tasktag(q, "my-tag");Note
If several tasks have the same tag, only one of them is cancelled. If you
want to cancel all the tasks with the same tag, you can use loop until
cancel_by_task does not return a task, as in:
while q->cancel_by_taskid("my-tag"):
passWorker Blacklist
You may find that certain hosts are not correctly configured to run your tasks. The manager can be directed to ignore certain workers with the blacklist feature. For example:
t = q.wait(5)
# if t fails given a worker misconfiguration:
q.blacklist(t.hostname)my $t = $q->wait(5);
# if $t fails given a worker misconfiguration:
$q->blacklist($t->hostname);struct work_queue_task *t = work_queue_wait(q, t);
//if t fails given a worker misconfiguration:
work_queue_blacklist_add(q, t->{hostname});Performance Statistics
The queue tracks a fair number of statistics that count the number of tasks, number of workers, number of failures, and so forth. This information is useful to make a progress bar or other user-visible information:
stats = q.stats
print(stats.workers_busy)my $stats = $q->stats;
print($stats->{task_running});struct work_queue_stats stats;
work_queue_get_stats(q, &stats);
printf("%d\n", stats->workers_connected);Managing Remote Tasks
With a RemoteTask, rather than sending the executable to run at a worker,
Work Queue simply sends the name of a function. This function is executed by a
coprocesses at the worker (i.e., in a serverless fashion). For short running
tasks, this may avoid initialization overheads, as the coprocess (e.g. a python
interpreter and its modules) is only initialized once, rather than every time
per function. To start a worker with a serverless coprocess, refer to the next
section about running workers.
Defining a RemoteTask involves specifying the name of the python function to execute,
as well as the name of the coprocess that contains that function.
coprocess.py
# this function is running on a worker's serverless coprocess
# the coprocess has the name "sum_coprocess"
def my_sum(x, y):
return x+ymanager.py
# task to execute x = my_sum(1, 2)
t = wq.RemoteTask("my_sum", "sum_coprocess", 1, 2)There are many ways to specify function arguments for a RemoteTask
# task to execute x = my_sum(1, 2)
# one way is by using purely positional arguments
t = wq.RemoteTask("my_sum", "sum_coprocess", 1, 2)
# keyword arguments are also accepted
t = wq.RemoteTask("my_sum", "sum_coprocess", x=1, y=2)
# arguments can be passed in as a dictionary
t = wq.RemoteTask("my_sum", "sum_coprocess", {x:1, y:2})
# or a mix and match of argument types can be used
t = wq.RemoteTask("my_sum", "sum_coprocess", 1, y=2)Additionally, there are three unique execution methods: direct, thread, and fork. Direct execution will have the worker's coprocess directly execute the function. Thread execution will have the coprocess spawn a thread to execute the function. Fork execution will have the coprocess fork a child process to execute the function.
# directly have the coprocess execute the function
t.specify_exec_method("direct")
# use a thread to execute the function
t.specify_exec_method("thread")
# fork a child process to execute the function
t.specify_exec_method("fork")Once a RemoteTask is executed on the worker's coprocess,
the output it returns (t.output) is a json encoded string.
json.loads(t.output) contains two keys: Result and StatusCode.
Result will contain the result of the function, or the text of an exception if one occurs.
StatusCode will have the value 200 if the function executes successfully, and 500 otherwise.
You can examine the result of a RemoteTask like this:
while not q.empty():
t = q.wait(5)
if t:
x = t.output
response = json.loads(t.output)
if response["StatusCode"] == 500:
print("Exception: {}".format(response["Result]))
else:
print("Result: {}".format(response["Result]))A RemoteTask inherits from Task and so all other methods for
controlling scheduling, managing resources, and setting performance options
all apply to RemoteTask as well.
The only difference is that RemoteTask tasks will only consume
worker resources allocated for its serverless coprocess, and not regular resources.
They also can not run on workers without the prerequisite coprocess.
Creating workers with serverless coprocesses
Running a RemoteTask requires a worker initialized with a serverless coprocess.
A serverless coprocess has a name and contains one or many Python functions.
These functions will exist for the lifetime of the worker and can be executed repeatedly.
For example, with the file functions.py below
def my_sum(x, y):
return x+y
def my_mult(x, y):
return x*yTo turn the functions "my_sum" and "my_mult" below into serverless functions: Run the command
poncho_package_serverize --src functions.py --function my_sum --function my_mult --dest coprocess.pyThis causes the functions my_sum and my_mult from the file functions.py
to be turned into a serverless coprocess in the file coprocess.py.
The name will be set to a default unless a function defined name exists
which returns the name of the coprocess.
def name():
return "arithmetic_coprocess"Once the functions have been turned into their serverless form, to start a worker with a serverless coprocess function, add the argument
--coprocess coprocess.pyThis will cause the worker to spawn an instance of the serverless coprocess at startup. The worker will then be able to receive and execute serverless functions if the name of its coprocess matches what was specified on the task.
Several options exist when starting workers with coprocesses. One is that workers can start an arbitrary number of coprocesses. For example, running the following command will have a worker start 4 instances of a coprocess.
--coprocess coprocess.py --num_coprocesses 4Each coprocess can independently receive and execute a RemoteTask, provided the worker has resources to do so.
The resources allocated to coprocesses on the worker can be specified as such.
--coprocess coprocess.py --coprocess_cores 4 --coprocess_disk 4 --coprocess_memory 1000 --coprocess_gpus 0Each coprocess will be given an equal share of the total number of coprocess resources allocated. For example, with 4 coprocesses and 4 coprocess cores, each coprocess will receive 1 core. These allocations are automatically monitored and offending coprocesses are terminated.
Python Abstractions
Map
The work_queue map abstraction works similar to python map, as it applies a a function to every element in a list. This function works by taking in a chunk_size, which is the size of an iterable to send to a worker. The worker than maps the given function over the iterable and returns it. All the results are then combined from the workers and returned. The size of the chunk depends on the cost of the function. If the function is very cheap, then sending a larger chunk_size is better. If the function is expensive, then smaller is better. If an invalid operation happens, the error will appear in the results.
def fn(a):
return a*a
q.map(fn, arry, chunk_size)Pair
The work_queue pair function computes all the pairs of 2 sequences, and then uses them as inputs of a given function. The pairs are generated locally using itertools, and then based on the given chunk_size, are sent out to a worker as an iterable of pairs. The given function must accept an iterable, as the pair will be sent to the function as a tuple. The worker will then return the results, and each result from each worker will be combined locally. Again, cheaper functions work better with larger chunk_sizes, more expensive functions work better with smaller ones. Errors will be placed in results.
def fn(pair):
return pair[0] * pair[1]
q.pair(fn, seq1, seq2, chunk_size)Tree Reduce
The work_queue treeReduce fucntion combines an array using a given function by breaking up the array into chunk_sized chunks, computing the results, and returning the results to a new array. It then does the same process on the new array until there only one element left and then returns it. The given fucntion must accept an iterable, and must be an associative fucntion, or else the same result cannot be gaurenteed for different chunk sizes. Again, cheaper functions work better with larger chunk_sizes, more expensive functions work better with smaller ones. Errors will be placed in results. Also, the minimum chunk size is 2, as going 1 element at time would not reduce the array
def fn(seq):
return max(seq)
q.treeReduce(fn, arry, chunk_size) Below is an example of all three abstractions, and their expected output:
import ndcctools.work_queue as wq
# Example funtion for the Map Abstraction
def dblfunc(x):
return 2*x
# Example function for the Pair Abstraction
# Note: function must accept a tuple
def mulfunc(p):
return p[0] * p[1]
# Example function for the Tree Reduce Abstraction
# Note: function must accept a iterable
def maxfunc(p):
return p[0] if p[0] > p[1] else p[1]
# Set up WorkQueue on port 9123
q = wq.WorkQueue(9123)
# Example arrays/sequences
a = [1, 2, 3, 4]
b = [2, 4, 6, 8]
# Map
results = q.map(dblfunc, a, 1)
print(f'Map: {results}')
# Pair
results = q.pair(mulfunc, a, b, 2)
print(f'Pair: {results}')
# Tree reduce
results = q.tree_reduce(maxfunc, b, 2)
print(f'Tree: {results}')
Run:
python abstractions.pyExpected output:
Map: [2, 4, 6, 8]
Pair: [2, 4, 6, 8, 4, 8, 12, 16, 6, 12, 18, 24, 8, 18, 24, 32]
Tree: 8Logging facilities
We can observe the lifetime of the queue through three different logs:
Debug Log
The debug log prints unstructured messages as the queue transfers files and tasks, workers connect and report resources, etc. This is specially useful to find failures, bugs, and other errors. To activate debug output:
q = wq.WorkQueue(debug_log = "my.debug.log")my $q = Work_Queue->new(debug_log => "my.debug.log");#include "debug.h"
cctools_debug_flags_set("all");
cctools_debug_config_file("my.debug.log");The all flag causes debug messages from every subsystem called by Work Queue
to be printed. More information about the debug flags are
here.
To enable debugging at the worker, set the -d option:
$ work_queue_worker -d all -o worker.debug -M myprojectStatistics Log
The statistics logs contains a time series of the statistics collected by Work Queue, such as number of tasks waiting and completed, number of workers busy, total number of cores available, etc. The log is activated as follows:
q = wq.WorkQueue(stats_log = "my.statslog")my $q = Work_Queue->new(stats_log => "my.stats.log");work_queue_specify_log(q, "my.stats.log");The time series are presented in columns, with the leftmost column as a timestamp in microseconds. The first row always contains the name of the columns. Here is an example of the first few rows and columns.
# timestamp workers_connected workers_init workers_idle workers_busy workers_...
1602165237833411 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 5 0 0 0 0 0 1602165237827668 ...
1602165335687547 1 0 0 1 1 1 0 0 0 0 0 0 4 1 0 0 5 0 0 0 0 0 1602165237827668 ...
1602165335689677 1 0 0 1 1 1 0 0 0 0 0 0 4 1 1 1 5 1 0 0 0 0 1602165237827668 ...
...The script work_queue_graph_log is a wrapper for gnuplot, and with it you
can plot some of the statistics, such as total time spent transfering tasks,
number of tasks running, and workers connected:
$ work_queue_graph_log -o myplots my.stats.log
$ ls *.png
$ ... my.stats.log.tasks.png my.stats.log.tasks-log.png my.stats.log.time.png my.stats.log.time-log.png ...We find it very helpful to plot these statistics when diagnosing a problem with work queue applications.
Transactions Log
Finally, the transactions log records the lifetime of tasks and workers. It is specially useful for tracking the resources requested, allocated, and used by tasks. It is activated as follows:
q = wq.WorkQueue(transactions_log = "my.tr.log")my $q = Work_Queue->new(transactions_log => "my.tr.log");work_queue_specify_transactions_log(q, "my.tr.log");The first few lines of the log document the possible log records:
# time manager_pid MANAGER START|END
# time manager_pid WORKER worker_id host:port CONNECTION
# time manager_pid WORKER worker_id host:port DISCONNECTION (UNKNOWN|IDLE_OUT|FAST_ABORT|FAILURE|STATUS_WORKER|EXPLICIT
# time manager_pid WORKER worker_id RESOURCES {resources}
# time manager_pid CATEGORY name MAX {resources_max_per_task}
# time manager_pid CATEGORY name MIN {resources_min_per_task_per_worker}
# time manager_pid CATEGORY name FIRST (FIXED|MAX|MIN_WASTE|MAX_THROUGHPUT) {resources_requested}
# time manager_pid TASK taskid WAITING category_name (FIRST_RESOURCES|MAX_RESOURCES) {resources_requested}
# time manager_pid TASK taskid RUNNING worker_address (FIRST_RESOURCES|MAX_RESOURCES) {resources_allocated}
# time manager_pid TASK taskid WAITING_RETRIEVAL worker_address
# time manager_pid TASK taskid (RETRIEVED|DONE) (SUCCESS|SIGNAL|END_TIME|FORSAKEN|MAX_RETRIES|MAX_WALLTIME|UNKNOWN|RESOURCE_EXHAUSTION) exit_code {limits_exceeded} {resources_measured}
# time manager_pid TRANSFER (INPUT|OUTPUT) taskid cache_flag sizeinmb walltime filenameLowercase words indicate values, and uppercase indicate constants. A bar (|) inside parentheses indicate a choice of possible constants. Variables encased in braces {} indicate a JSON dictionary. Here is an example of the first few records of a transactions log:
1599244364466426 16444 MASTER START
1599244364466668 16444 TASK 1 WAITING default FIRST_RESOURCES {"cores":[1,"cores"],"memory":[800,"MB"],"disk":[500,"MB"]}
1599244364466754 16444 TASK 2 WAITING default FIRST_RESOURCES {"cores":[1,"cores"],"memory":[800,"MB"],"disk":[500,"MB"]}
...With the transactions log, it is easy to track the lifetime of a task. For example, to print the lifetime of the task with id 1, we can simply do:
$ grep 'TASK \<1\>' my.tr.log
1599244364466668 16444 TASK 1 WAITING default FIRST_RESOURCES {"cores":[1,"cores"],"memory":[800,"MB"],"disk":[500,"MB"]}
1599244400311044 16444 TASK 1 RUNNING 10.32.79.143:48268 FIRST_RESOURCES {"cores":[4,"cores"],"memory":[4100,"MB"],...}
1599244539953798 16444 TASK 1 WAITING_RETRIEVAL 10.32.79.143:48268
1599244540075173 16444 TASK 1 RETRIEVED SUCCESS 0 {} {"cores":[1,"cores"],"wall_time":[123.137485,"s"],...}
1599244540083820 16444 TASK 1 DONE SUCCESS 0 {} {"cores":[1,"cores"],"wall_time":[123.137485,"s"],...}The statistics available are:
| Field | Description |
|---|---|
| Stats for the current state of workers | |
| workers_connected | Number of workers currently connected to the manager |
| workers_init | Number of workers connected, but that have not send their available resources report yet |
| workers_idle | Number of workers that are not running a task |
| workers_busy | Number of workers that are running at least one task |
| workers_able | Number of workers on which the largest task can run |
| Cumulative stats for workers | |
| workers_joined | Total number of worker connections that were established to the manager |
| workers_removed | Total number of worker connections that were released by the manager, idled-out, fast-aborted, or lost |
| workers_released | Total number of worker connections that were asked by the manager to disconnect |
| workers_idled_out | Total number of worker that disconnected for being idle |
| workers_fast_aborted | Total number of worker connections terminated for being too slow |
| workers_blacklisted | Total number of workers blacklisted by the manager (includes fast-aborted) |
| workers_lost | Total number of worker connections that were unexpectedly lost (does not include idled-out or fast-aborted) |
| Stats for the current state of tasks | |
| tasks_waiting | Number of tasks waiting to be dispatched |
| tasks_on_workers | Number of tasks currently dispatched to some worker |
| tasks_running | Number of tasks currently executing at some worker |
| tasks_with_results | Number of tasks with retrieved results and waiting to be returned to user |
| Cumulative stats for tasks | |
| tasks_submitted | Total number of tasks submitted to the queue |
| tasks_dispatched | Total number of tasks dispatch to workers |
| tasks_done | Total number of tasks completed and returned to user (includes tasks_failed) |
| tasks_failed | Total number of tasks completed and returned to user with result other than WQ_RESULT_SUCCESS |
| tasks_cancelled | Total number of tasks cancelled |
| tasks_exhausted_attempts | Total number of task executions that failed given resource exhaustion |
| Manager time statistics (in microseconds) | |
| time_when_started | Absolute time at which the manager started |
| time_send | Total time spent in sending tasks to workers (tasks descriptions, and input files) |
| time_receive | Total time spent in receiving results from workers (output files) |
| time_send_good | Total time spent in sending data to workers for tasks with result WQ_RESULT_SUCCESS |
| time_receive_good | Total time spent in sending data to workers for tasks with result WQ_RESULT_SUCCESS |
| time_status_msgs | Total time spent sending and receiving status messages to and from workers, including workers' standard output, new workers connections, resources updates, etc. |
| time_internal | Total time the queue spents in internal processing |
| time_polling | Total time blocking waiting for worker communications (i.e., manager idle waiting for a worker message) |
| time_application | Total time spent outside work_queue_wait |
| Wrokers time statistics (in microseconds) | |
| time_workers_execute | Total time workers spent executing done tasks |
| time_workers_execute_good | Total time workers spent executing done tasks with result WQ_RESULT_SUCCESS |
| time_workers_execute_exhaustion | Total time workers spent executing tasks that exhausted resources |
| Transfer statistics | |
| bytes_sent | Total number of file bytes (not including protocol control msg bytes) sent out to the workers by the manager |
| bytes_received | Total number of file bytes (not including protocol control msg bytes) received from the workers by the manager |
| bandwidth | Average network bandwidth in MB/S observed by the manager when transferring to workers |
| Resources statistics | |
| capacity_tasks | The estimated number of tasks that this manager can effectively support |
| capacity_cores | The estimated number of workers' cores that this manager can effectively support |
| capacity_memory | The estimated number of workers' MB of RAM that this manager can effectively support |
| capacity_disk | The estimated number of workers' MB of disk that this manager can effectively support |
| capacity_instantaneous | The estimated number of tasks that this manager can support considering only the most recently completed task |
| capacity_weighted | The estimated number of tasks that this manager can support placing greater weight on the most recently completed task |
| total_cores | Total number of cores aggregated across the connected workers |
| total_memory | Total memory in MB aggregated across the connected workers |
| total_disk | Total disk space in MB aggregated across the connected workers |
| committed_cores | Committed number of cores aggregated across the connected workers |
| committed_memory | Committed memory in MB aggregated across the connected workers |
| committed_disk | Committed disk space in MB aggregated across the connected workers |
| max_cores | The highest number of cores observed among the connected workers |
| max_memory | The largest memory size in MB observed among the connected workers |
| max_disk | The largest disk space in MB observed among the connected workers |
| min_cores | The lowest number of cores observed among the connected workers |
| min_memory | The smallest memory size in MB observed among the connected workers |
| min_disk | The smallest disk space in MB observed among the connected workers |
| manager_load | In the range of [0,1]. If close to 1, then the manager is at full load and spends most of its time sending and receiving taks, and thus cannot accept connections from new workers. If close to 0, the manager is spending most of its time waiting for something to happen. |
The script work_queue_graph_workers is an interactive visualization tool for
Work Queue transaction logs based on Python bokeh package. It can be used to
visualize the life time of tasks and workers, as well as diagnosing the effects
of file transfer time on overall performance. See
work_queue_graph_workers(1) for
detailed information.
Specialized and Experimental Settings
The behaviour of Work Queue can be tuned by the following parameters. We advise caution when using these parameters, as the standard behaviour may drastically change.
| Parameter | Description | Default Value |
|---|---|---|
| category-steady-n-tasks | Minimum number of successful tasks to use a sample for automatic resource allocation modes after encountering a new resource maximum. |
25 |
| proportional-resources | If set to 0, do not assign resources proportionally to tasks. The default is to use proportions. (See task resources. | 1 |
| proportional-whole-tasks | Round up resource proportions such that only an integer number of tasks could be fit in the worker. The default is to use proportions. (See task resources. | 1 |
| hungry-minimum | Smallest number of waiting tasks in the queue before declaring it hungry | 10 |
| hungry-minimum-factor | Queue is hungry if number of waiting tasks is less than hungry-minumum-factor x (number of workers) | 2 |
| ramp-down-heuristic | If set to 1 and there are more workers than tasks waiting, then tasks are allocated all the free resources of a worker large enough to run them. If monitoring watchdog is not enabled, then this heuristic has no effect. | 0 |
| resource-submit-multiplier | Assume that workers have resource x resources-submit-multiplier available.This overcommits resources at the worker, causing tasks to be sent to workers that cannot be immediately executed. The extra tasks wait at the worker until resources become available. |
1 |
| wait-for-workers | Do not schedule any tasks until wait-for-workers are connected. |
0 |
| wait-retrieve-many | Rather than immediately returning when a task is done, q.wait(timeout) retrieves and dispatches as many tasksas timeout allows. Warning: This may exceed the capacity of the manager to receive results. |
0 |
q.tune("hungry-minumum", 20)$q->tune("hungry-minumum", 20)work_queue_tune(q, "hungry-minumum", 20)Further Information
For more information, please see Getting Help or visit the Cooperative Computing Lab website.
Copyright
CCTools is Copyright (C) 2022 The University of Notre Dame. This software is distributed under the GNU General Public License Version 2. See the file COPYING for details.